|
|
|
|
|
|
|
|
|
|

|
|
|
|
Letzte Aktualisierung: 04.01.2023
|
|
Strings in C++, VB und ATL
Strings werden in verschiedenen Sprachen unterschiedlich behandelt.
Diese Unterschiede muß man kennen, wenn man "gemischte" Projekte erstellen will, in denen Strings übergeben werden.
Es kommt noch hinzu, daß zunehmend sogenannte "Unicode" - Strings Verwendung finden, die die Repräsentation
von verschiedenen Zeichensätzen und von Sonderzeichen erleichtern.
Auch hierbei gibt es einiges zu beachten.
Der folgende Artikel erklärt die technischen Grundlagen zur Stringbehandlung in C und C++, Visual Basic und ATL,
und zeigt, wie man mit Unicode - Strings arbeiten kann.
Wie wird ein String intern dargestellt ?
Was ist Unicode ?
Wie kann man mit Unicode programmieren ?
Buchtips
|
Wie wird ein String intern dargestellt ?
Ein String ist, einfach gesagt, erstmal nur eine Kette von einzelnen Zeichen oder Buchstaben.
Der Einfachheit halber gehen wir zunächst mal davon aus, daß jedes Zeichen im Speicher genau ein Byte Platz benötigt,
denn das war früher immer so, und ist auch heute noch sehr weit verbreitet. Dann sieht ein typischer String im
Speicher etwa so aus (ein Kästchen soll ein Byte / Speicherstelle darstellen) :

Der Pfeil steht dabei für einen Zeiger auf den String-Anfang, denn in dieser Zeiger-Form werden Strings in allen
hier genannten Sprachen intern verwaltet.
Jetzt muß es für Programme noch eine Möglichkeit geben, zu Wissen, wo der String zu Ende ist; schließlich ist
der Speicher nicht in solche Fünferblöcke eingeteilt, wie oben dargestellt, sondern er ist eigentlich eine
Art lineares Band. Es muß also irgendwie erkennbar werden, wo der String zu Ende ist.
Und hier unterscheiden sich jetzt einige Sprachen. In C++ ist es so, wie es in C schon immer war: Ein String
wird hinten durch ein spezielles Zeichen begrenzt, nämlich durch ein Null-Byte. Dieses nennt man auch Terminator.
In C ist ein String immer ein
Array von Charactern, und die Variable selbst ist ein Zeiger auf den Anfang.

Nur durch das Null-Byte am Ende (das hier nicht mit einer "0" gekennzeichnet ist, weil es sonst mit der Text-"0"
verwechselt wird) wird das Ende erkannt, und so wird auch die Länge des Strings ermittelt: Es wird vom Anfang an
so lange gesucht und gezählt, bis das Null-Byte gefunden wird.
In Visual Basic geht es anders: Dort heißt der Variablentyp "String", und er hat eine Besonderheit. Anstatt eines
Terminator - Bytes steht dort die Länge des Strings VOR dem String selbst, in einer long - Variable (4 Bytes lang).
Somit ist eindeutig definiert, wie lang der String ist:
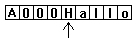
Die eigentliche String-Variable zeigt dabei weiterhin auf den Start der Zeichenkette. Die Zahlen davor sind die
vier Bytes, die die String-Länge angeben. Auf Intel - Systemen wird immer das niederwertigste Byte zuerst gespeichert, so
daß die dargestellte Zahl hexadezimal 0x000A lauten würde, in Dezimalform entspricht das der Zahl 10. Warum 10 ?
Der String ist doch nur 5 Zeichen lang ? Hier zeigt sich eine Besonderheit: Die Längenangabe im BSTR gibt nicht die Länge
in Zeichen an, sondern die Länge in Bytes. Wie im nächsten Abschnitt (Unicode) gezeigt wird, haben viele Strings
aber zwei Bytes pro Zeichen, und das ist auch beim BSTR der Fall, deshalb stehen hier 10 Bytes für 5 Zeichen.
(Randbemerkung: Wer sich mit C++ auskennt, und sich von letzterem überzeugen möchte, kann dieses dreizeilige Testprojekt einmal anschauen, damit kann man den Inhalt der Längenangabe prüfen).
Manchmal wird in VB aber auch eine Terminator - Null hinten dran gehangen, ich habe nur noch nicht herausgefunden,
wann genau. Der Hintergrund ist folgender: Die Win32 - API - Funktionen sind alle im "C - Stil" geschrieben, das
heißt das die Funktionen, die einen String als Parameter erwarten, einen String in Form eines Character - Arrays
wie in C erwarten. Das würde mit den VB - Strings dann problemlos gehen, wenn eine Terminator - Null zusätzlich hinten dran
wäre. Und es funktioniert auch, man kann aus VB heraus die API - Funktionen aufrufen, und als Strings kann man
dabei reine VB - Strings einsetzen, sofern diese nicht von der API - Funktion verändert werden.
Wenn die API - Funktion den String auch noch verändern will, dann gibt es immer einen zusätzlichen Parameter in der
API - Funktion, über den man dazusagen kann, wieviele Zeichen man dafür reserviert hat. Auch solche Funktionen kann
man aus VB heraus aufrufen. Man muß nur vorher über den Befehl "MeinString = Space(128)" dafür sorgen, daß in der
übergebenen String - Variablen auch wirklich soviele Zeichen reserviert werden, wie man es der API-Funktion mitteilt,
in diesem Fall also z.B. 128 Zeichen. Dabei muß man nur noch eines beachten: MeinString ist an dieser Stelle mit 128
Leerzeichen (Spaces) gefüllt worden, und in den 4 Längen-Bytes vornedran steht dann auch, daß der String 128 Zeichen
lang ist. Die API - Funktion kennt diese Längenangabe nicht; sie füllt den String von der ersten Stelle an so lange, bis sie fertig ist, und macht
hinten den Null - Terminator dran. Das könnte zum Beispiel ein 5 Byte langer String sein, mit der Null an Stelle 6.
Visual Basic sieht den String jedoch nach wie vor als 128 Zeichen langen String an, weil die Längenangabe vorne für
VB entscheidend ist. Daher muß man nach einer solchen API - Funktion in der Regel noch den VB - Befehl "Trim" auf
einen solchen String anwenden, also etwa "MeinString = Trim(MeinString)". Dadurch werden die Spaces und das Null-Byte
hinten "abgeschnitten", und die Längenangabe wird anschließend aktualisiert.
|
Was ist Unicode ?
Bisher wurde stets davon ausgegangen, daß ein Zeichen in ein Byte hineinpaßt, und dies hat auch einige Jahre problemlos
funktioniert. Nun lassen sich in einem Byte aber maximal 256 verschiedene Zeichen darstellen. Unser Alphabet hat zwar
nur 26 Zeichen, aber die übrigen Zeichen waren ebenfalls schnell reserviert, sei es für Steuerzeichen, Leerzeichen,
Symbole und so weiter. Die ersten 127 Zeichen sind als "ASCII" - Tabelle bekannt und enthalten alle Klein- und Großbuchstaben
des lateinischen Alphabets. Häufige Verwendung findet auch die "ANSI" - Tabelle, die in den ersten 127 Zeichen mit ASCII
übereinstimmt, und in den hinteren 128 Zeichen weitere Zeichen enthält, unter anderem auch die deutschen Umlaute.
Es hat sich jedoch gezeigt, daß ein Byte einfach zuwenig ist, um alle möglichen Zeichen aus allen Welt - Alphabeten
einheitlich darzustellen. Also wurde Unicode als Standard erfunden. Unicode ist eine Zeichentabelle, die 32767 verschiedene
Zeichen ermöglicht, weil jedes Zeichen 2 Byte (= 16 Bit) groß ist. Dort passen locker alle bekannten Alphabete hinein,
inklusive China und Japan, die ja sehr viele Schriftzeichen besitzen. Auch Symbole wie Euro, Dollar und britisches Pfund
haben dort ihren eindeutigen Platz. Der Nachteil ist jedoch, daß jedes Zeichen nun 16 Bit Platz braucht, und daß dies natürlich
Texte und Strings auf die doppelte Größe aufbläht.
Microsoft war hier sehr weit vorausschauend und hat in den frühen neunziger Jahren das Betriebssystem "Windows NT" von den
Wurzelspitzen her auf Unicode ausgelegt.
Dieses Betriebssystem war der Vorgänger von Windows 2000, und dieses wiederum von Windows XP und Windows Server 2003.
Alle internen Stringverarbeitungsoperationen werden mit Unicode - Zeichen durchgeführt,
und für Anwendungen hat man die Wahl, ob man mit Unicode oder 8-Bit-ANSI-Zeichen arbeiten möchte. Fast alle API - Funktionen,
die einen String als Parameter erhalten oder zurückgeben, gibt es daher in zwei Varianten, einmal als 16-Bit und einmal
als 8-Bit-Variante. Wenn eine Funktion hinten ein großes "A" wie ANSI hat, ist es die 8-Bit-Variante, hat sie hinten ein
großes "W" (für wide string), so ist es die 16-Bit-Variante. Es ist sogar so, daß Anwendungen, die konsequent auf 16-Bit-Zeichen
hin programmiert sind, etwas schneller laufen als solche, die teilweise oder überwiegend mit 8-Bit-Zeichen arbeiten,
weil das Betriebssystem auf die Unicode - Strings optimiert ist, und weniger hin- und her konvertiert werden muß.
Woher weiß jetzt eine Textverarbeitung wie Word oder Notepad, ob in einer Textdatei, die geöffnet werden soll, Unicode
oder 1-Byte-Zeichen verwendet werden ? Es hat sich durchgesetzt, daß Unicode - Textdateien stets mit den beiden Bytes "FF FE"
beginnen, daran wird diese Erkennung festgemacht. Daher sollte man diesen Code auch selbst verwenden, wenn man Unicode-Dateien erzeugt.
Mehr über Unicode: www.unicode.org
|
Wie kann man mit Unicode programmieren ?
Für Visual Basic ist diese Frage sehr schnell beantwortet: Bis zur Version 3.0 wurde automatisch mit ANSI gearbeitet,
aber der Version 4.0 wird Unicode verwendet. Daran kann man nichts ändern durch irgendwelche Einstellungen. Es ist dabei
so, daß für API - Aufrufe (s.o.) automatisch von Unicode in ANSI konvertiert wird, ohne daß man etwas dazutun muß. Das heißt
aber auch, daß man in VB immer diejenigen API - Funktionen verwenden muß, die hinten ein großes "A" haben, sofern man
die Auswahl hat. Auch beim Schreiben von Strings in eine Datei konvertiert VB automatisch von Unicode in ANSI.
In C und C++ ist die Sache anders. Dort kann man durch Definition einer Compiler-Anweisung angeben, wie man standardmäßig
mit Strings umgehen will. Das hindert einen aber nicht daran, bewußt auch "gemischt" zu programmieren, es ist eben dann kein
guter Stil. Die Compiler-Anweisungen sind:
MBCS, _MBCS für ANSI - Zeichen (steht für "Multi Byte Character Set") UNICODE, _UNICODE für Unicode - Zeichen
Die erste Variante ist standardmäßig eingestellt, wenn man ein neues Projekt in C++ 6.0 beginnt. Ich habe jeweils zwei
Konstanten genannt, und verwende auch stets alle beide, weil es von Microsoft - Komponenten nicht durchgängig mit einer einzigen
Definition verstanden wird, was man will. Diese Konstanten sorgen dann automatisch dafür, daß hinter API - Funktionen ein
"A" oder "W" hinten drangehangen wird. Außerdem sorgen sie dafür, daß sogenannte "Template" - Makros und Funktionen, auf die
ich gleich noch komme, richtig übersetzt werden. Und wenn die MFC verwendet werden, dann werden auch diese in der Unicode -
Variante benutzt.
Während früher nur der Datentyp für 8-Bit-Zeichen, "char", zum Einsatz kam, gibt es seit einiger Zeit auch einen Datentyp
für 16-Bit-Zeichen, nämlich "wchar_t". Damit kann man analog zu den bisher gewohnten String - Operationen arbeiten, nur
heißen die Funktionen dann alle etwas anders, statt "strlen()" nimmt man dann "wcslen()" zur Berechnung der Stringlänge.
Diese anderen Namen sind aber alle sehr gut dokumentiert; in jeder Doku zu einer alten Funktion steht auch gleich daneben,
wie der entsprechende Name für 16-Bit-Strings lautet. Worüber man als Anfänger häufig stolpert, ist, daß jetzt die Stringlänge
und die Bytelänge nicht mehr identisch sind. Aber man gewöhnt sich dran. Auch der Terminator ist jetzt eine Doppel-Null.
Warum hat dieser Datentyp einen so bescheuerten Namen, "wchar" hätte es doch auch getan ? Nun, ich denke diese
Abkürzung steht für "wide character type", und diese Abkürzung hat sich dann historisch irgendwie eingebürgert.
Manchmal möchte man eine Zeichenkette als Konstante hinterlegen, zum Beispiel bei der Zuweisung an einen konstanten String:
const wchar_t * lpszUeberschrift = L"Fehlermeldung";
Das einzig neue, was zu beachten ist, ist das große "L". Es sagt dem Compiler, daß der konstante String aus 16-Bit-Zeichen
bestehen soll. Andernfalls bekommt man auch eine Fehlermeldung beim compilieren.
Lieber Leser, Sie müssen nun recht tapfer sein, denn im Folgenden werden sehr viele Kürzel erklärt,
die einen erst einmal "erschlagen", die aber alle eine gewisse Systematik haben, an die man sich recht schnell gewöhnt.
Ich fange an mit den Abkürzungen für verschiedene Arten von Zeichenketten, so wie sie durchgehend durch die Microsoft / MSDN - Dokumentation verwendet werden:
LPSTR ist dasselbe wie "char *" ("long pointer to string") LPWSTR ist dasselbe wie "wchar_t *" ("long pointer to wide string") OLESTR ist auch dasselbe wie "wchar_t *" (historisch überholt) LPCSTR ist dasselbe wie "const char *" ("long pointer to const string") LPCWSTR ist dasselbe wie "const wchar_t *" ("long pointer to const wide string") BSTR steht für "Basic String", ein Datentyp, der gleich noch erklärt wird.
Lassen Sie sich nicht davon verwirren, daß dies alles Großbuchstaben sind; es handelt sich nicht um Makros oder Konstanten, sondern einfach um Abkürzungen für die Datentypen, die hier beschrieben werden.
Auch Konvertierungen sind möglich. Dafür gibt es zwei API - Funktionen: MultiByteToWideChar und WideCharToMultiByte.
Weil diese Funktionen aber sehr viele Parameter haben, und jedesmal spezielle Puffer für die Konvertierung bereitzustellen sind,
gibt es sehr bequeme Makros, die die Konvertierungsarbeit erledigen (definiert in ATLCONV.H):
A2W(LPSTR) konvertiert einen 8-Bit-String (char *) in einen 16-Bit-String (wchar_t *) W2A(LPSTR) konvertiert einen 16-Bit-String (wchar_t *) in einen 8-Bit-String (char *) A2CW(LPSTR) konvertiert einen 8-Bit-String (char *) in einen konstanten 16-Bit-String (const wchar_t *) W2CA(LPSTR) konvertiert einen 16-Bit-String (wchar_t *) in einen konstanten 8-Bit-String (const char *)
Als Eselsbrücke ist dabei gedacht, daß "2" ja "two" heißt und so klingt wie "to", so daß z.B. "A2W" steht für "ANSI to Wide".
Damit diese Funktionen keine Compilerfehler erzeugen, muß in derselben Funktion irgendwo davor folgende Zeile eingetragen werden:
USES_CONVERSION;
Diese Zeile ist ein Makro, welches einen lokalen Puffer reserviert, der nachher bei der Konvertierung das Ergebnis aufnimmt.
Daher ist das Ergebnis der Konvertierung auch immer physikalisch zu kopieren (z.B. mit strcpy), und nicht einfach per Zuweisung zu übertragen:
char * pErgebnis = W2A(lpszWideString); /* Fehler ! pErgebnis zeigt jetzt nur auf den Puffer, der in der nächsten Operation überschrieben wird ! */
Es wurde schonmal angedeutet, daß es auch Template - Funktionen und Makros gibt. Diese Funktionen werden vom Preprozessor
entsprechend behandelt, je nachdem wie die Compiler - Anweisung (MBCS / UNICODE) eingestellt ist. Ein Beispiel:
TCHAR * lpszMeldung = _T("Datei nicht da!");
Diese Zeile wird folgendermaßen übersetzt: Wenn "MBCS" eingestellt ist, wird daraus:
char * lpszMeldung = "Datei nicht da!";
und wenn UNICODE eingestellt ist, wird daraus:
wchar_t * lpszMeldung = L"Datei nicht da!";
Somit kann man auch Code schreiben, der je nach Compilereinstellung passend zur Umgebung compiliert. Man erkennt die
entsprechenden Makros und Funktionen alle daran, daß ein "T" enthalten ist. Beispielsweise ist "_tcscpy" die Template-
Funktion, die je nach Compilereinstellung zu "strcpy" wird, oder eben zu "wcscpy".
Auch ein weiterer Sonderling wurde schonmal kurz genannt, der BSTR. Dieser Datentyp ist genau das, was weiter oben
als String unter Visual Basic beschrieben wurde (der mit der 4-Byte-Längenangabe), daher hat er auch seinen Namen ("Basic String"). Er ist allerdings immer
mit 16-Bit-Zeichen gefüllt, es gibt ihn nicht als 8-Bit-Variante. Und, auch wichtig, die Längenangabe vor dem String ist
NICHT die Byte-Länge, sondern die Anzahl der Zeichen. Der BSTR hat deswegen so eine große Bedeutung, weil er der String-
Datentyp ist, der über COM - Schnittstellen verwendet werden darf. Wenn man in C++ eine COM - Komponente schreibt, dann
muß in der IDL - Datei für Strings dieser BSTR verwendet werden.
Um es nochmal deutlich zu machen: wchar_t und BSTR sind beides Zeiger auf 16-Bit Zeichenketten, beide sind Doppel-Null-terminiert,
aber nur der BSTR hat vor dem eigentlichen String diese genannte Längenangabe (4-Byte-Integer). Es gibt in der Microsoft - Dokumentation
mindestens eine Stelle, an der gewarnt wird, daß der BSTR nicht immer zwingend mit einer Doppel - Null terminiert wird, einziges sicheres Mittel
zur Bestimmung der gültigen Zeichen ist die Längenangabe vor dem String (die 4 Bytes). In meiner wahrhaftig langjährigen Praxis bin ich aber noch
nie auf einen BSTR gestoßen, der nicht mit Doppel - Null terminiert war. Wer aber ganz auf Nummer sicher gehen will, sollte diesen Hinweis trotzdem beachten.
In VB wird der BSTR also sowieso automatisch verwendet ... wie verwendet man diese Datenstruktur jetzt in C++ ? Dazu
ein kleines Beispiel:
BSTR bsMeldung;
bsMeldung = SysAllocString(L"Falsche Eingabe!");
pComObjekt->ZeigeMeldung(bsMeldung);
SysFreeString(bsMeldung);
Zu Beachten ist, daß man nicht selbständig die Datenstruktur manipuliert, sondern immer nur die dafür vorgesehenen
Funktionen aufruft:
SysAllocString() zum Erzeugen (allokieren) eines Strings SysFreeString() zum Befreien eines allokierten Strings SysStringLen() zur Abfrage der Stringlänge
Eine Besonderheit ist, daß der Wert "NULL" in einer BSTR - Objektvariablen durchaus erlaubt ist, dies repräsentiert einen leeren
String. Und man muß höllisch aufpassen, daß man seinen String auch immer wieder schön befreit, sonst ballert man sich
ganz schnell den Speicher zu.
Um Sicherzustellen, daß man nicht vergißt, jeden BSTR wieder freizugeben, und um das Handling zu vereinfachen, gibt es
in der ATL - Bibliothek zwei spezielle Klassen, nämlich CComBSTR und _bstr_t. Diese beiden Klassen kapseln intern ein BSTR - Objekt,
um den Umgang damit zu vereinfachen. Man kann für so einen CComBSTR oder auch einen _bstr_t einfach einen Konstruktor
aufrufen, indem man einen 16-Bit-String mitgibt, oder man kann auch den leeren Kontruktor nutzen, und diesen Objekten
dann später mit dem "=" Operator Strings zuweisen. Diese Objekte räumen selbst ihren Speicher wieder auf, das
erledigt der Destruktor. Man kann die enthaltenen BSTR - Objekte dann mit einem simplen cast ("(BSTR)") verwenden.
Ein interessanter Artikel mit einem kleinen Tool zum Verarbeiten verschiedener Unicode-Dateien: http://www.codeproject.com/KB/files/EZUTF.aspx
|
Buchtips

|
"Professional ATL COM" von Dr. Richard Grimes bietet einen guten Einstieg in die Programmierung
mit ATL - Templates. Es wird auch sehr viel COM - Hintergrundwissen vertieft, wer also nur ein einziges Bich sucht,
und die COM - Grundlagen kennt, sollte eher zu diesem Buch greifen.
Die Active Template Library (ATL) ist eine Art Framework für die COM - Programmierung, welches dem Entwickler eine
Menge an Arbeit abnimmt, und ihm trotzdem die volle Kontrolle läßt. Es ist aber nur etwas für C++ - Entwickler,
in Visual Basic hat man keine Chance, damit zu arbeiten.
Informationen zum Buch
|

|
"Visual Basic 6" von Michael Kofler ist der Klassiker unter den Lehrbüchern für Visual Basic.
Das Buch ist sowohl für den Einsteiger interessant, als auch als Referenzwerk für den Profi. Es deckt im Grunde
alles ab, was man über Visual Basic 6 wissen muß.
Informationen zum Buch
|
|
Support, Feedback, Anregungen
Alles verstanden ? Oder noch Fragen ? Wir freuen uns über Feedback zu den Tips, auch über Verbesserungsvorschläge.
Schreiben Sie an support@a-m-i.de.
|
|
